Prospective FAIRification of Data on the EDISON platform – Roche
Roche embeds data standards and quality checks to harmonize, automate and integrate very heterogeneous and complex processes.
- Self-contained micro services deliver performance and scalability
- Scalable and flexible for data models in clinical and non-clinical

Overview
What if we can help make our data FAIR even before it enters our company? As a large pharmaceutical company, we asked ourselves this question as we realized that we spend too much time to find, access and pool data and that retrospective FAIRification of data is not sustainable for the long-term. We are building the EDISON platform to enable prospective FAIRification of data at the point of entry to Roche, by harmonizing, automating and integrating very heterogeneous & complex processes across multiple departments, building in data standards and quality checks at every step of the process.
The EDISON platform is built as an ecosystem of self-contained micro services to ensure maximum performances, scalability and low maintenance. The current scope of EDISON is clinical non-CRF data but the platform is scalable and flexible to cover large variety of data models, both clinical and non-clinical.
Process
EDISON is an in-house built, GCP validated platform that addresses some of the root causes of low data quality by harmonizing and automating the process in which clinical sample metadata and non-CRF data is defined, acquired and shared for further analysis. The core concepts behind the platform are data blueprints that describe the data that should enter Roche, leveraging global data standards and well-defined terminologies, and a flexible quality service that allows the data to be quality assured as early as possible in the process and thereby avoiding cumbersome and resource intensive internal integration and curation efforts afterwards. The FAIR data is then stored in central repositories that provide access via web interface or API to downstream repositories and processes.
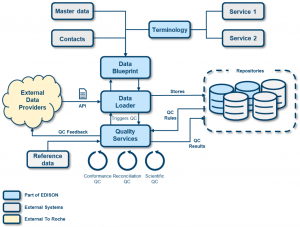
Figure 1: The EDISON informatics landscape.
Figure 1 illustrates how the user starts by defining the data blueprint describing the dataset. Once the data blueprint is completed, a data provider can upload the data either by file upload or via direct API connection. Once the data has been uploaded, it is saved in a data repository and a number of quality checks can be executed on the data with instantaneous feedback to the users.
The EDISON platform consists of the following components:
Data Blueprint Designer
The data blueprint designer allows the user to electronically define their dataset (data record specification, contacts, assay information, etc…) with a user-friendly interface, including life cycle management and version control. The use of internal data standards and terminology services ensures the quality and reusability of the data. The system will highlight any deviations from existing standards, e.g. changes in controlled terminology, format changes etc….
Data Loader
The data loader module allows for direct access to the EDISON platform for data providers (internal or external) to upload data for an approved data blueprint, either by file upload or with an API connection. After storing the data upload, the EDISON platform performs an immediate conformance check on the uploaded data. The conformance checks analyses if the uploaded data meets the requirements set in the data blueprint. Once the conformance check has been completed the data provider receives an immediate feedback and visualization of the issues found.
Reconciliation Checks
The reconciliation checks focus on assessing the completeness and correctness of the data versus data that was previously defined and entered into, for example, clinical data systems (CRF data), such as patient IDs and visits or other reference systems.
Scientific Quality Check
The scientific quality checks allow scientists to define and run specific data checks on particular data sets. For example, for genetic biomarkers the system analyses Hardy-Weinberg equilibrium, Sample Call Rate, Variant Call Rate, Minor Allele Frequency, Multi Allelic Variants and provides the user with a clear visual feedback on the quality of the data.
The process of the data blueprint definition, data upload and all quality checks is stored in the EDISON platform and can be visualized using dashboards that are provided as part of the platform.
Outcomes
The EDISON platform has been in productive use since Q4 2019 and it currently in use for early adopters at Roche. We have on-boarded six external vendors that access and upload data directly to the platform and we are currently running 10 clinical studies as a part of the early adopter phase. The platform is still under development with additional vendors and studies on-boarded every month.
At a Glance
Team
- Project Manager
- Business Analysts
- Validation Team
- Software Developers
Timeline
- A validated productive release with additional functionality every 3 months
- The project under its current scope will run for 12 months
Benefits and deliverables
- Enabling prospective FAIRification eliminating the need for resource intensive retrospective efforts
- Harmonizing, automating, integrating and digitalization of paper-based processes
- Standardized terminology that links and maps variables from multiple sources
Author
Top Tips
- Co-creation between business and informatics and an agile way of working is the key to success
- Scalable and flexible cloud architecture will ensure that such a complex platform is future proof
- Don’t be afraid to challenge current processes and try out innovative ideas