FAIRification of clinical trial data – Roche
Hear more about Roche’s ‘learning-by-doing’ FAIRification efforts
- Lessons learned from FAIRification of clinical data for Ophthalmology, Autism, Asthma and COPD
- Set up integrated end-to-end process for curation workflows for prospective studies

Overview
Roche has a wealth of clinical trial data collected over several decades across many indications. In 2017 a collaborative, cross-functional and multi-year program was launched to transform our data management practices and corporate culture. The key objective was to accelerate the generation of new medical treatments through FAIR and shared data. While the long term goal is to FAIRify all datasets, we decided to embrace a “learning-by-doing” approach in the initial phase. Therefore, we launched a series of use cases with smaller data sets to answer specific scientific questions prioritized by a scientific steering committee. This approach led to the identification of issues and challenges associated with FAIRfying legacy data. In addition, it resulted in a deeper understanding of what is needed to improve and build into our future data management ecosystem to make data FAIR by design. Last but not least, we had to shift the mindset within the organization along the way, on the “FAIR journey”.
Process
The goal has been to FAIRify legacy datasets in different Therapeutic Areas (TA) but also to design processes for prospective FAIRification of future studies. The initial approach included the following steps:
-
- Define and prioritize use cases and identify related studies. Factors to consider are age and relevance of a dataset or the importance of a study for driving translational research.
- Locate the datasets, related documents and study teams.
- Ensure data privacy by restricting access based on Study Informed Consent Forms (ICFs) and status of study. Internal data access and sharing principles are published in a FAIR format (RDF) and can be attributed to datasets in the Roche data catalog
- Assess which parts of the data need to be FAIRified (do we need to clean up everything? Or only data that will be relevant for translational research?)
- Define process and resources to FAIRify data
- Apply reference data to harmonize and standardize study data using Clinical Data Interchange Standards Consortium (CDISC; https://www.cdisc.org/standards) and sponsor extensions. Roche’s reference data fully comply with the FAIR principles e.g. using Unified Resource Identifiers (URIs) for data and metadata as well as Resource Description Framework (RDF) vocabularies for representation
- Run mapping and transformation pipelines on the study to generate a FAIR representation.
- Apply final quality control according to curation guidelines and assess FAIRness.
- Publish FAIRified datasets in a data catalogue annotated with the DCAT (https://www.w3.org/TR/vocab-dcat-3/) vocabulary
- Assess value through close interaction with the data scientists.
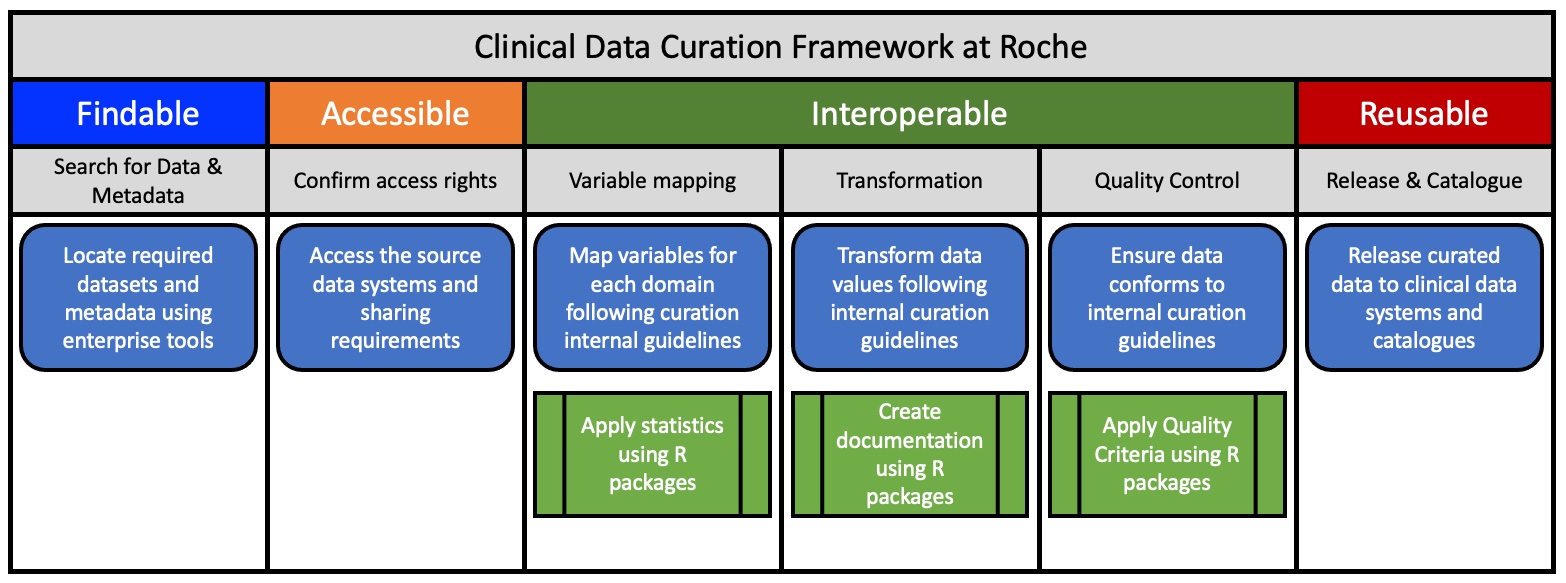 Figure 1: The Curation Framework at Roche for Clinical Data.
Figure 1: The Curation Framework at Roche for Clinical Data.
Outcomes
FAIR annotation of clinical data has been implemented successfully in four Therapeutic Areas : Ophthalmology, Autism, Asthma and COPD. The overall progress in Data FAIRIfication has improved our processes for better curation and management of data and metadata. Three important learnings emerged from this work.
Firstly, we observed that data consisted of different models over the years due to inconsistent application of standards. Secondly, we identified several issues regarding the Findability and Accessibility of data due to the size of the company, evolution of systems and people leaving the company or moving to other groups, clearly proving the value of a FAIR data representation. The third, most important issue is a cultural one: the lack of awareness among the various clinical study teams about the benefits of FAIR data. Not everyone sees the potential value of historical clinical data and metadata, how it can inform drug discovery groups helping to design faster and shorter clinical trials and support information-based decision making in the R&D pipeline.
It is our experience that FAIR Implementation for clinical data requires a seismic shift to a data-centric culture, applied by everyone as best practice. We have been able to set up an integrated end-to-end process for curation workflows and systems to enable data FAIRifcation at scale. A FAIR operationalization group has been formed to advise, design and deploy methodologies to determine and improve the FAIRness of clinical data and metadata. This includes the application of FAIR Maturity indicators to evaluate the level of FAIRness and the education of our clinical scientists on the value of implementing the FAIR principles across all clinical functions.
References and Resources
- Khan, Z., Hammer, C., Carroll, J. et al. Genetic variation associated with thyroid autoimmunity shapes the systemic immune response to PD-1 checkpoint blockade. Nat Commun 12, 3355 (2021). https://doi.org/10.1038/s41467-021-23661-4
- Data Catalog Vocabulary (DCAT) – Version 3: https://www.w3.org/TR/vocab-dcat-3/
- Clinical Data Interchange Standards Consortium (CDISC): https://www.cdisc.org/standards
At a Glance
Team
- Project Managers
- Data Curators
- Data Integrators
- Data Standard Specialists
- Software developers
Timeline
- One year for initial learnings, second year to implement tools and technology
Benefits and deliverables
- Data for more than 150k patients has been curated
- Data analyses results have been presented as posters in conferences
Author
Top Tips
- Start small – think big: Initiate a small number of high-value studies with representative indications to identify the core issues.
- Shift the mindset: Educate and excite people about the perspectives of FAIR data
- Keep the scientists and analysts in the loop at every step of the process.
FAQs
What was the first step in the curation process?
First step is to find the datasets and get access to the data.
What was the challenging part about curation?
The challenging part was to work out what is the community ‘standard’ that we need to bring all the data to, how to control the quality of the curated data and how to document on the curation process.
What tools are needed for curation?
A selection of tools are needed which depend on the scope and extent of curation. We evaluated several external tools against our curation requirements and finally decided to develop curation tools in-house.