Data Granularity and Context
Consider how the granularity and context of data and associated metadata to help to inform your FAIR objectives.
- Understand the granularity and context of the data as early as possible
Overview
The phenomenal growth of Life Science data makes it more important than ever to invest in support for the life cycle of data management which is enhanced by making the data FAIR, being Findable, Accessible. Interoperable and Reusable [1]. This method considers the granularity of data and the context of application to identify to inform the FAIR objectives. This will help to determine which Maturity Indicators are likely to be most important for improvement [2]. The method described here is designed to inform which FAIR Maturity Indicators are expected to be the most important to improve so that the data can be ingested by machine and human-assisted workflows for processing, storage, integration, finding and application [3,4], as illustrated in Figure 1 below.
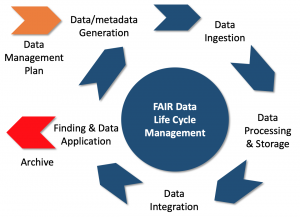
Figure 1: Management of the FAIR data life cycle
How To
The following questions about granularity and context for the data and metdata should be considered, prior to making the data FAIR (FAIRification) either through a process of retrospective transformation or by proactive design. Multiple choice answers can be given but if a question prompts inprecise, uncertain or unknown answers then further study of feasibility will be required to gain more precise answers in an iterative manner from domain experts and other likely end users of the data. Analysis of these answers will foster the need for a Data Management Plan and help to determine the most valuable Maturity Indicators for making the data more FAIR.
- What levels of granularity are appropriate for the data and metadata?
- a. Catalogue
- b. Collection
- c. Set
- d. Type of content; e.g. raw, derived, numeric or categoric
- e. Transformed
- f. Unknown
- Points to MIs for FINDABILITY
- What types of scientific competency question [4] are most important for the data and metadata?
- a. Compound
- b. Target
- c. Pathway
- d. Disease
- e. Other
- f. Unknown
- Points to MIs for FINDABILITY & INTEROPERABILITY
- When will the data and metadata be reviewed for value?
- a. How many years?
- b. Is this longevity supported by a retention policy?
- c. When will the data be archived or deleted?
- d. How is the metadata supported as a permanent record of the science?
- e. Unknown
- Points to the need for a DATA MANAGEMENT PLAN
- Will the data and metadata need to be found by a web search engine?
- a. Yes
- b. No
- c. Unknown
- Points to MIs for FINDABILITY
- Who needs to access to the data and metadata?
- a. Named individuals
- b. Named groups
- c. Name project or function
- d. Organisation wide
- e. External access by registered people
- f. Public access by any individual
- g. Unknown
- Points to MIs for ACCESSIBILITY
- How important is it to integrate this dataset with other sources?
- a. Important
- b. Desirable
- c. Unimportant
- d. Unknown
- Points to MIs for FINDABILITY & INTEROPERABILITY
- How precious is the dataset?
- a. Rare and expensive
- b. Rare or expensive
- c. Common and cheap
- d. Common or cheap
- e. Unknown
- Points to MIs for REUSABILITY
- What is the provenance for the data?
- a. Reproduced by a trusted source
- b. Published in a peer-reviewed journal
- c. Assertion or claim
- d. Unknown
- Points to MIs for REUSABILITY
- Is there freedom to use the data?
- a. Data is owned by the organisation
- b. Usage license is available
- c. Data is public but no license to define usage
- d. Unknown
- Points to MIs for REUSABILITY
References and Resources
- Wilkinson et al The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data volume3, Article number: 160018 https://doi.org/10.1038/sdata.2016.18
- Vogt, L. Levels and building blocks—toward a domain granularity framework for the life sciences. J Biomed Semant 10, 4 (2019). https://doi.org/10.1186/s13326-019-0196-2
- Griffin et al Best practice data life cycle approaches for the life sciences. Version 2. F1000Res. 2017 Aug 31 [revised 2018 Jun 4]; 6:1618. https://doi.org/10.12688/f1000research.12344.2
- Azzaoui et al Scientific competency questions as the basis for semantically enriched open pharmacological space development. Drug Discovery Today. 2013 Sep;18(17-18):843-52. https://doi.org/10.1016/j.drudis.2013.05.008
Resources
At a Glance
Related methods
Setting
- Granularity and context of the data should be considered early as possible
Team
- Scientist generating or collecting the data and metadata
- Data steward
Timing
- 1-2 day timeframe for gathering answers
Difficulty
- Low to Medium
Resources
Top Tips
- Inprecise, uncertain or unknown answers prompted by this set of questions requires further study of feasibility.
- Domain experts and likely end users of the data should be consulted in an iterative manner to gain sufficiently precise answers.