FAIRification Workflow
Find out how a generic workflow can be deployed by workshops or action team to make important datasets FAIR.
- FAIRification as a retroactive workflow is common at this time
- FAIRification by design (data “born” FAIR) is far more desirable for the future
Overview
This method is a step-by-step, generic workflow for making data FAIR, often known as “FAIRification”. It can be deployed by workshops or a team of subject matter experts guided by FAIR data stewards as published by Jacobsen et al at Leiden University and GO-FAIR International Support & Coordination Office [1]. These authors describe how it should be applicable generically to any type of data (and metadata) and how it has emerged from a series of “Bring Your Own Data” (BYOD) workshops. A related methodology has been developed by the IMI FAIRplus project who have deployed FAIRification squad teams [2] and collating specific protocols as “recipes” for FAIRification in the FAIR cookbook [3].
The figure below shows how the FAIRification workflow is divided into three “phases”: Pre-FAIRification, FAIRification, and Post-FAIRification (dark grey boxes) that are further specified by “steps” indicating typical aspects of practical FAIRification (light grey boxes): 1) identify FAIRification objectives, 2) analyse data, 3) analyse metadata, 4) define the semantic model for data (4a) and metadata (4b), 5) make data (5a) and metadata (5b) linkable 6) host FAIR data and metadata and 7) assess FAIR data and metadata for meeting the objective.
The order of the steps in the workflow is not strict, can be iterative and some of the FAIRification steps maybe optional. The practical deployment of this workflow is shown in the figure below which will depend on the data source, use case, domain or FAIRification objective.
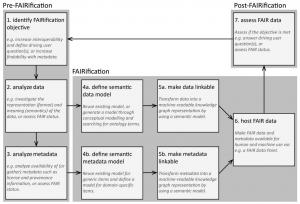
This FAIRification workflow should be used as a template which the authors [1] expect continuous evolution. This may include planning (e.g. DMP) and inventory phases or FAIRification by design (e.g. before starting data collection) rather than FAIRification of an existing dataset.
How To
- Identify FAIRification objectives: This pre-FAIRification step requires a general knowledge and understanding of an existing or planned dataset. Preparation of the Data Management Plan (DMP) and consideration of the granularity and context of the data (see the corresponding FAIR Toolkit methods) can help with defining the objectives.
- The FAIR objectives could focus on an initial subset of data elements. The workflow can then be iterated so more data elements can be included later.
- Data subset selection can be driven by user questions that require at least two data resources. Another driver could be to improve the associated metadata.
- Analyse data: This pre-FAIRification step makes an initial assessment of the data using the FAIR Maturity Indicators (MI) on the selected dataset, prior to FAIRification. See the four FAIR MI methods of this Toolkit.
- Analyse metadata: This pre-FAIRification step makes an initial assessment of the metadata using the FAIR MI methods of this Toolkit.
- Define semantic data and metadata model (Steps 4a and 4b): A FAIRification step to define a semantic model as a template to transform the data and metadata into a machine-readable format. Reuse of existing semantic models is preferred but if a new one needs to be generated this process is described by Jacobsen et al [1]. Briefly, this involves a) making a conceptual model, b) searching ontological terms, and 3) creating a semantic data model from a) and b).
- An alternative is to adapt or develop a common data model which includes FAIR compliant attributes.
- Make data and metadata linkable (Steps 5a and 5b): This FAIRification step to make data and metadata linkable is highly application and use case dependent. It enables machine readability for unforeseen future applications and scalable interoperability across all types of data.
- An example of a linkable machine-readable global framework is the Resource Description Framework (RDF).
- Host FAIR data: A FAIRification step for consumption by human and machine use through different interfaces, such as Application Programming Interface (API), RDF triple store, data warehouse, Web application or metadata repository [4].
- Assess FAIR data: A post-FAIRification step to assess the improved transformation of the FAIR data and metadata. This will include checking whether the original objectives as defined in step 1 have been achieved through manual or automated evaluation of the FAIR Mis to compare with the initial results. Further iteration through these workflow steps maybe required to achieve the FAIR objectives.
References and Resources
- Jacobsen, R. Kaliyaperumal, L.O. Bonino da Silva Santos, B. Mons, E. Schultes, M. Roos & M. Thompson. A generic workflow for the data FAIRification process. Data Intelligence 2(2020), 56–65. doi: 10.1162/dint_a_00028
- FAIRfication squad teams by FAIRplus: https://fairplus-project.eu/about/how-project-organised#squads
- The FAIR Cookbook by FAIRplus: https://fairplus.github.io/the-fair-cookbook
Resources
- FAIR Cookbook
- The FAIR Cookbook is a repository that hosts documentation, known as FAIR recipes, and supporting code in the form of jupyter notebooks about FAIRification processes.
- The content will be released regularly (quarterly) in order to reflect the progress made by the FAIRplus project and the various working groups, which bring together academic and industry partners.
- COLID – Quick start
- Corporate Linked Data – short: COLID by Bayer AG
- A data catalogue for corporate environments that provides a metadata repository for data assets based upon semantic models
- COLID also assigns URIs as persistent and global unique identifiers to any resource. The incorporated network proxy ensures that these URIs are resolvable and can be used to directly access those assets.
At a Glance
Related use cases
- FAIRifying collaborative research on Real World Data – The Hyve
-
Prospective FAIRification of data on the EDISON platform – Roche
Related methods
- BYOD datathon workshops
- Data Management Plans
- Data granularity and context
- Data Capability Maturity Model
- FAIR Maturity Indicator methods
Setting
- Applicable to existing datasets
Team(s)
- Data Steward(s)
- Relevant Subject Matter Expert(s)
Timing
- 2 days for pre and post-FAIRification
- These might be workshops
- Time for FAIRification depends on
- the FAIR objective
- the complexity of the dataset(s)
- the complexity of the use case
Difficulty
- Low for pre and post-FAIRification
- Medium to high for FAIRification