Findability Maturity Indicators
Find out how to apply the FAIR Maturity Indicators to measure the FINDABILITY of the data and metadata.
- Findability of data is compared with your FAIR objectives to identify and make improvements in an iterative manner
Overview
Implementation of the FAIR guidelines is measured by a framework of metrics which are now termed as Maturity Indicators (MI) [1, 2, 3]. This method is focussed on the maturity indicators to measure the findability of the data and metadata. It is a questionnaire for manual evaluation of the FAIR MIs for Findability which are recorded in the FAIRsharing registry [4,5]. It is important to understand that FAIR is intended to be aspirational. This means that any FAIR evaluation MIs are used to understand how to improve the FAIRness of the data.
The FAIR MIs are now reaching 2nd generation maturity as a result of community feedback and the need to automate FAIR evaluation, which is available as a public demonstrator developed by Mark Wilkinson and collaborators [6, 7]. The 2nd generation MIs have been adopted for this method to prepare for automated evaluation when they are ready for production usage by industry. All currently available FAIR evaluation tools and services have been compared by Research Data Alliance [8] who have recently released the FAIR Data Model: specification and guidelines [9].
The MIs for Findability are illustrated below:
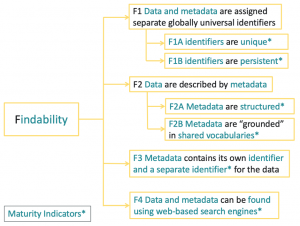
How To
These questions are MIs that enable manual evaluation of Findability.
- Are the Globally Universal Identifiers (GUID) for the data and the metadata unique?
- Indicates whether the identifiers match (through regular expression) a GUID scheme recognized as being globally unique in a relevant registry (e.g. external FAIRsharing.org or internal from COLID).
- Examples: URLs and DOIs
- DOI: 10.25504/FAIRsharing.NHCOKK (Gen2-MI-F1A)
- Indicates whether the identifiers match (through regular expression) a GUID scheme recognized as being globally unique in a relevant registry (e.g. external FAIRsharing.org or internal from COLID).
- Are the identifiers for data and metadata persistent (identifiers are the same as for Q1)?
- Indicates whether the identifier for the data and metadata matches (through regular expression) a GUID scheme recognized as being persistent.
- Examples: purl, oclc, fdlp, purlz, w3id, ark
- DOI: 10.25504/FAIRsharing.VRo9Dl (Gen2-MI-F1B)
- Indicates whether the identifier for the data and metadata matches (through regular expression) a GUID scheme recognized as being persistent.
- Does the metadata contain “structured” elements?
- Indicates whether the metadata of the data contains “structured” elements.
- Examples: Hash-like content (micrograph, JSON) or linked data (JSON-LD, RDFa, etc.).
- DOI: 10.25504/FAIRsharing.2dUpZs (Gen2-MI-F2A)
- Indicates whether the metadata of the data contains “structured” elements.
- Are the metadata “grounded” in shared vocabularies?
- Indicates whether the metadata of the data contains “structured” elements that are “grounded” in shared FAIR vocabularies.
- Example: Linked data (JSON-LD, RDFa, Turtle, etc.).
- DOI: 10.25504/FAIRsharing.lXAOu2 (Gen2-MI-F2B)
- Indicates whether the metadata of the data contains “structured” elements that are “grounded” in shared FAIR vocabularies.
- Does the metadata document contain its own identifier and another for the data (also, the same as for Q1 & 2)?
- Indicates whether the metadata includes both its own identifier and whether it also explicitly contains the identifier for the data it describes (same as Q1).
- Examples: URLs and DOIs
- DOI: 10.25504/FAIRsharing.5Xy1dJ (Gen2-MI-F3)
- Indicates whether the metadata includes both its own identifier and whether it also explicitly contains the identifier for the data it describes (same as Q1).
- Does the data have a Unique Resource Locator (URL) so it can be found using web-based search engines?
- Indicates the degree to which the data can be found using a web-based search engine.
- Example: URL
- DOI: 10.25504/FAIRsharing.x1f1l4 (Gen2-MI-F4)
- Indicates the degree to which the data can be found using a web-based search engine.
References and Resources
- The FAIR metrics group repository on GitHub at fairmetrics.org
- Wilkinson et al 2018 A design framework and exemplar metrics for FAIRness. Scientific Data volume5, Article number: 180118 (DOI: 10.1038/sdata.2018.118).
- Supplementary information for Wilkinson et al 2018: https://github.com/FAIRMetrics/Metrics/tree/master/Evaluation_Of_Metrics
- FAIR Maturity Indicators and Tools: https://github.com/FAIRMetrics/Metrics/tree/master/MaturityIndicators
- FAIRsharing registry search for FAIR metrics: https://fairsharing.org/standards/?q=FAIR+maturity+indicator
- Second generation Maturity Indicators tests: https://github.com/FAIRMetrics/Metrics/tree/master/MaturityIndicators/Gen2
- A public demonstration server for The FAIR Evaluator: https://w3id.org/AmIFAIR
- Research Data Alliance 2020 Results of an Analysis of Existing FAIR assessment tools: https://preview.tinyurl.com/yausl4s4
- Research Data Alliance 2020 FAIR Data Maturity Model: specification and guidelines: https://preview.tinyurl.com/y5tgby6w
Resources
- COLID – Quick start
- Corporate Linked Data – short: COLID by Bayer AG
- A technical solution for corporate environments that assigns URIs as persistent and global unique identifiers to any resource. The incorporated network proxy ensures that these URIs are resolvable and can be used to directly access those assets.
- COLID also provides a metadata repository for corporate assets based upon semantic models.
- Identifiers.org
- This service provides resolvable and public identifiers for findable and accessible data in the life sciences.
- Compact identifiers are stored in the registry of identifiers.org
- FAIRsharing
- A curated, informative and educational resource on data and metadata standards, inter-related to databases and data policies.
- Guides consumers to discover, select and use these resources with confidence, and producers to make their resource more discoverable, more widely adopted and cited.
- ISA Tools
- This framework provides a rich description of experimental metadata.
- It is built around the ‘Investigation’ (the project context), ‘Study’ (a unit of research) and ‘Assay’ (analytical measurement) data model and serializations (tabular, JSON and RDF)
- CEDAR workbench
- This workbench for metadata management is designed for development, evaluation, use and refinement of biomedical metadata.
- Metadata templates in CEDAR define the data elements needed to describe particular types of biomedical experiment.
- FAIR Evaluator
- This public demonstrator uses the 2nd generation MIs.
- The evaluation results are returned much faster than manual evaluation.
- RDA FAIR Data Maturity Model
- Specification, guidelines and evaluation (manual sheet)
At a Glance
Related methods
- Accessibility FAIR Maturity Indicators
- Interoperability FAIR Maturity Indicators
- Reusability FAIR Maturity Indicators
- FAIRification workflow
Setting
- Evaluation of findability to improve the FAIRness of the data and metadata
Team
- Data steward
- Scientist generating or collecting the data and metada
Timing
- 0.5 day to answer the questions by manual assessment.
- This will be reduced if an automated FAIR evaluator is deployed.
- Additional time will be required to make the data more FAIR driven by the objectives
- This will be reduced if the data is FAIR by design (“born FAIR”)
Difficulty
- Medium
Resources
Top Tips
- How FAIR are your data? Checklist by Sara Jones & Marjan Grootveld
- While FAIR MIs test for the presence of identifiers and structural elements they do not measure the quality of the data which may need to be evaluated as a separate exercise using appropriate criteria of fitness.
- The FAIR MIs are not an end in themselves; they indicate how data can be made more FAIR.
- Choices on which FAIR improvement to implement should be driven by feasibility and likely benefit, including return on investment.